Table of Contents
- 15.1. Introduction
- 15.2. Overview
- 15.3. Creating Storage Engine Source Files
- 15.4. Creating the
handlerton - 15.5. Handling Handler Instantiation
- 15.6. Defining Filename Extensions
- 15.7. Creating Tables
- 15.8. Opening a Table
- 15.9. Implementing Basic Table Scanning
- 15.10. Closing a Table
- 15.11. Adding Support for
INSERTto a Storage Engine - 15.12. Adding Support for
UPDATEto a Storage Engine - 15.13. Adding Support for
DELETEto a Storage Engine - 15.14. Supporting Non-Sequential Reads
- 15.15. Supporting Indexing
- 15.15.1. Indexing Overview
- 15.15.2. Getting Index Information During
CREATE TABLEOperations - 15.15.3. Creating Index Keys
- 15.15.4. Parsing Key Information
- 15.15.5. Providing Index Information to the Optimizer
- 15.15.6. Preparing for Index Use with
index_init() - 15.15.7. Cleaning up with
index_end() - 15.15.8. Implementing the
index_read()Function - 15.15.9. Implementing the
index_read_idx()Function - 15.15.10. Implementing the
index_next()Function - 15.15.11. Implementing the
index_prev()Function - 15.15.12. Implementing the
index_first()Function - 15.15.13. Implementing the
index_last()Function
- 15.16. Supporting Transactions
- 15.17. API Reference
- 15.17.1. bas_ext
- 15.17.2. close
- 15.17.3. create
- 15.17.4. delete_row
- 15.17.5. delete_table
- 15.17.6. external_lock
- 15.17.7. extra
- 15.17.8. index_end
- 15.17.9. index_first
- 15.17.10. index_init
- 15.17.11. index_last
- 15.17.12. index_next
- 15.17.13. index_prev
- 15.17.14. index_read_idx
- 15.17.15. index_read
- 15.17.16. info
- 15.17.17. open
- 15.17.18. position
- 15.17.19. records_in_range
- 15.17.20. rnd_init
- 15.17.21. rnd_next
- 15.17.22. rnd_pos
- 15.17.23. start_stmt
- 15.17.24. store_lock
- 15.17.25. update_row
- 15.17.26. write_row
With MySQL 5.1, MySQL AB has introduced a pluggable storage engine architecture that makes it possible to create new storage engines and add them to a running MySQL server without recompiling the server itself.
This architecture makes it easier to develop new storage engines for MySQL and deploy them.
This chapter is intended as a guide to assist you in developing a storage engine for the new pluggable storage engine architecture.
Additional resources
A forum dedicated to custom storage engines is available at http://forums.mysql.com/list.php?94.
The MySQL server is built in a modular fashion:
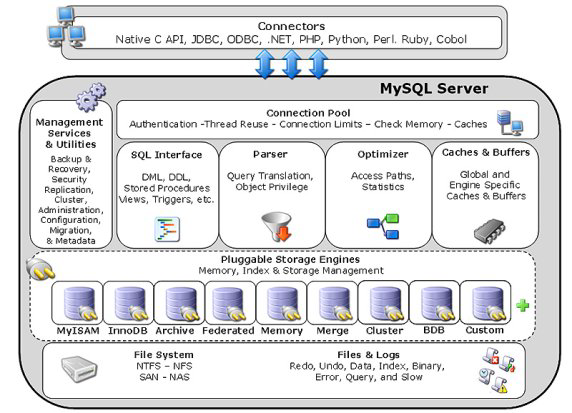
The storage engines manage data storage and index management for MySQL. The MySQL server communicates with the storage engines through a defined API.
Each storage engine is a class with each instance of the class
communicating with the MySQL server through a special
handler interface.
Handlers are instanced on the basis of one handler for each thread that needs to work with a specific table. For example: If three connections all start working with the same table, three handler instances will need to be created.
Once a handler instance is created, the MySQL server issues commands to the handler to perform data storage and retrieval tasks such as opening a table, manipulating rows, and managing indexes.
Custom storage engines can be built in a progressive manner:
Developers can start with a read-only storage engine and later add
support for INSERT, UPDATE,
and DELETE operations, and even later add
support for indexing, transactions, and other advanced operations.
The easiest way to implement a new storage engine is to begin by
copying and modifying the EXAMPLE storage
engine. The files ha_example.cc and
ha_example.h can be found in the
storage/example directory of the MySQL 5.1
source tree. For instructions on how to obtain the 5.1 source
tree, see Section 2.8.3, “Installing from the Development Source Tree”.
When copying the files, change the names from
ha_example.cc and
ha_example.h to something appropriate to your
storage engine, such as ha_foo.cc and
ha_foo.h.
After you have copied and renamed the files you must replace all
instances of EXAMPLE and
example with the name of your storage engine.
If you are familiar with sed, these steps can
be done automatically (in this example, the name of your storage
engine would be “FOO”):
sed s/EXAMPLE/FOO/g ha_example.h | sed s/example/foo/g ha_foo.h sed s/EXAMPLE/FOO/g ha_example.cc | sed s/example/foo/g ha_foo.cc
The handlerton (short for “handler
singleton”) defines the storage engine and contains
function pointers to those functions that apply to the storage
engine as a whole, as opposed to functions that work on a
per-table basis. Some examples of such functions include
transaction functions to handle commits and rollbacks.
Here's an example from the EXAMPLE storage
engine:
handlerton example_hton= {
"EXAMPLE",
SHOW_OPTION_YES,
"Example storage engine",
DB_TYPE_EXAMPLE_DB,
NULL, /* Initialize */
0, /* slot */
0, /* savepoint size. */
NULL, /* close_connection */
NULL, /* savepoint */
NULL, /* rollback to savepoint */
NULL, /* release savepoint */
NULL, /* commit */
NULL, /* rollback */
NULL, /* prepare */
NULL, /* recover */
NULL, /* commit_by_xid */
NULL, /* rollback_by_xid */
NULL, /* create_cursor_read_view */
NULL, /* set_cursor_read_view */
NULL, /* close_cursor_read_view */
example_create_handler, /* Create a new handler */
NULL, /* Drop a database */
NULL, /* Panic call */
NULL, /* Release temporary latches */
NULL, /* Update Statistics */
NULL, /* Start Consistent Snapshot */
NULL, /* Flush logs */
NULL, /* Show status */
NULL, /* Replication Report Sent Binlog */
HTON_CAN_RECREATE
};
This is the definition of the handlerton from
handler.h:
typedef struct
{
const char *name;
SHOW_COMP_OPTION state;
const char *comment;
enum db_type db_type;
bool (*init)();
uint slot;
uint savepoint_offset;
int (*close_connection)(THD *thd);
int (*savepoint_set)(THD *thd, void *sv);
int (*savepoint_rollback)(THD *thd, void *sv);
int (*savepoint_release)(THD *thd, void *sv);
int (*commit)(THD *thd, bool all);
int (*rollback)(THD *thd, bool all);
int (*prepare)(THD *thd, bool all);
int (*recover)(XID *xid_list, uint len);
int (*commit_by_xid)(XID *xid);
int (*rollback_by_xid)(XID *xid);
void *(*create_cursor_read_view)();
void (*set_cursor_read_view)(void *);
void (*close_cursor_read_view)(void *);
handler *(*create)(TABLE *table);
void (*drop_database)(char* path);
int (*panic)(enum ha_panic_function flag);
int (*release_temporary_latches)(THD *thd);
int (*update_statistics)();
int (*start_consistent_snapshot)(THD *thd);
bool (*flush_logs)();
bool (*show_status)(THD *thd, stat_print_fn *print, enum ha_stat_type stat);
int (*repl_report_sent_binlog)(THD *thd, char *log_file_name, my_off_t end_offset);
uint32 flags;
} handlerton;
There are a total of 30 handlerton elements, only a few of which
are mandatory (specifically the first four elements and the
create() function).
The name of the storage engine. This is the name that will be used when creating tables (
CREATE TABLE ... ENGINE =).FOO;The value to be displayed in the
statusfield when a user issues theSHOW STORAGE ENGINEScommand.The storage engine comment, a description of the storage engine displayed when using the
SHOW STORAGE ENGINEScommand.An integer that uniquely identifies the storage engine within the MySQL server. The constants used by the built-in storage engines are defined in the
handler.hfile. Custom engines should useDB_TYPE_CUSTOM.A function pointer to the storage engine initializer. This function is only called once when the server starts to allow the storage engine class to perform any housekeeping that is necessary before handlers are instanced.
The slot. Each storage engine has its own memory area (actually a pointer) in the
thd, for storing per-connection information. It is accessed asthd->ha_data[. The slot number is initialized by MySQL afterfoo_hton.slot]foo_init()thd, see Section 15.16.3, “Implementing ROLLBACK”.The savepoint offset. To store per-savepoint data the storage engine is provided with an area of a requested size (
0, if no savepoint memory is necessary).The savepoint offset must be initialized statically to the size of the needed memory to store per-savepoint information. After
foo_initFor more information, see Section 15.16.5.1, “Specifying the Savepoint Offset”.
Used by transactional storage engines, clean up any memory allocated in their slot.
A function pointer to the handler's
savepoint_set()function. This is used to create a savepoint and store it in memory of the requested size.For more information, see Section 15.16.5.2, “Implementing the
savepoint_setFunction”.A function pointer to the handler's
rollback_to_savepoint()function. This is used to return to a savepoint during a transaction. It's only populated for storage engines that support savepoints.For more information, see Section 15.16.5.3, “Implementing the
savepoint_rollback() Function”.A function pointer to the handler's
release_savepoint()function. This is used to release the resources of a savepoint during a transaction. It's optionally populated for storage engines that support savepoints.For more information, see Section 15.16.5.4, “Implementing the
savepoint_release() Function”.A function pointer to the handler's
commit()function. This is used to commit a transaction. It's only populated for storage engines that support transactions.For more information, see Section 15.16.4, “Implementing COMMIT”.
A function pointer to the handler's
rollback()function. This is used to roll back a transaction. It's only populated for storage engines that support transactions.For more information, see Section 15.16.3, “Implementing ROLLBACK”.
Required for XA transactional storage engines. Prepare transaction for commit.
Required for XA transactional storage engines. Returns a list of transactions that are in the prepared state.
Required for XA transactional storage engines. Commit transaction identified by XID.
Required for XA transactional storage engines. Rollback transaction identified by XID.
Called when a cursor is created to allow the storage engine to create a consistent read view.
Called to switch to a specific consistent read view.
Called to close a specific read view.
MANDATORY - Construct and return a handler instance.
For more information, see Section 15.5, “Handling Handler Instantiation”.
Used if the storage engine needs to perform special steps when a schema is dropped (such as in a storage engine that uses tablespaces).
Cleanup function called during server shutdown and crashes.
InnoDB-specific function.InnoDB-specific function called at start ofSHOW ENGINE InnoDB STATUS.Function called to begin a consistent read.
Called to indicate that logs should be flushed to reliable storage.
Provides human readable status information on the storage engine for
SHOW ENGINE.fooSTATUSInnoDB-specific function used for replication.Handlerton flags that indicate the capabilities of the storage engine. Possible values are defined in
sql/handler.hand copied here:#define HTON_NO_FLAGS 0 #define HTON_CLOSE_CURSORS_AT_COMMIT (1 << 0) #define HTON_ALTER_NOT_SUPPORTED (1 << 1) #define HTON_CAN_RECREATE (1 << 2) #define HTON_FLUSH_AFTER_RENAME (1 << 3) #define HTON_NOT_USER_SELECTABLE (1 << 4)
HTON_ALTER_NOT_SUPPORTEDis used to indicate that the storage engine cannot acceptALTER TABLEstatements. TheFEDERATEDstorage engine is an example.HTON_FLUSH_AFTER_RENAMEindicates thatFLUSH LOGSmust be called after a table rename.HTON_NOT_USER_SELECTABLEindicates that the storage engine should not be shown when a user callsSHOW STORAGE ENGINES. Used for system storage engines such as the dummy storage engine for binary logs.
The first method call your storage engine needs to support is the call for a new handler instance.
Before the handlerton is defined in the storage
engine source file, a function header for the instantiation
function must be defined. Here is an example from the
CSV engine:
static handler* tina_create_handler(TABLE *table);
As you can see, the function accepts a pointer to the table the handler is intended to manage, and returns a handler object.
After the function header is defined, the function is named with a
function pointer in the create()
handlerton element, identifying the function as
being responsible for generating new handler instances.
Here is an example of the MyISAM storage
engine's instantiation function:
static handler *myisam_create_handler(TABLE *table)
{
return new ha_myisam(table);
}
This call then works in conjunction with the storage engine's
constructor. Here is an example from the
FEDERATED storage engine:
ha_federated::ha_federated(TABLE *table_arg)
:handler(&federated_hton, table_arg),
mysql(0), stored_result(0), scan_flag(0),
ref_length(sizeof(MYSQL_ROW_OFFSET)), current_position(0)
{}
And here's one more example from the EXAMPLE
storage engine:
ha_example::ha_example(TABLE *table_arg)
:handler(&example_hton, table_arg)
{}
The additional elements in the FEDERATED
example are extra initializations for the handler. The minimum
implementation required is the handler()
initialization shown in the EXAMPLE version.
Storage engines are required to provide the MySQL server with a list of extensions used by the storage engine with regard to a given table, its data and indexes.
Extensions are expected in the form of a null-terminated string
array. The following is the array used by the
CSV engine:
static const char *ha_tina_exts[] = {
".CSV",
NullS
};
This array is returned when the
bas_ext()
function is called:
const char **ha_tina::bas_ext() const
{
return ha_tina_exts;
}
By providing extension information you can also omit implementing
DROP TABLE functionality as the MySQL server
will implement it for you by closing the table and deleting all
files with the extensions you specify.
Once a handler is instanced, the first operation that will likely be required is the creation of a table.
Your storage engine must implement the
create()
virtual function:
virtual int create(const char *name, TABLE *form, HA_CREATE_INFO *info)=0;
This function should create all necessary files but does not need to open the table. The MySQL server will call for the table to be opened later on.
The *name parameter is the name of the table.
The *form parameter is a
TABLE structure that defines the table and
matches the contents of the
tablename.frmtablename.frm
The *info parameter is a structure containing
information on the CREATE TABLE statement used
to create the table. The structure is defined in
handler.h and copied here for your
convenience:
typedef struct st_ha_create_information
{
CHARSET_INFO *table_charset, *default_table_charset;
LEX_STRING connect_string;
const char *comment,*password;
const char *data_file_name, *index_file_name;
const char *alias;
ulonglong max_rows,min_rows;
ulonglong auto_increment_value;
ulong table_options;
ulong avg_row_length;
ulong raid_chunksize;
ulong used_fields;
SQL_LIST merge_list;
enum db_type db_type;
enum row_type row_type;
uint null_bits; /* NULL bits at start of record */
uint options; /* OR of HA_CREATE_ options */
uint raid_type,raid_chunks;
uint merge_insert_method;
uint extra_size; /* length of extra data segment */
bool table_existed; /* 1 in create if table existed */
bool frm_only; /* 1 if no ha_create_table() */
bool varchar; /* 1 if table has a VARCHAR */
} HA_CREATE_INFO;
A basic storage engine can ignore the contents of
*form and *info, as all that
is really required is the creation and possibly the initialization
of the data files used by the storage engine (assuming the storage
engine is file-based).
For example, here is the implementation from the
CSV storage engine:
int ha_tina::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
char name_buff[FN_REFLEN];
File create_file;
DBUG_ENTER("ha_tina::create");
if ((create_file= my_create(fn_format(name_buff, name, "", ".CSV",
MY_REPLACE_EXT|MY_UNPACK_FILENAME),0,
O_RDWR | O_TRUNC,MYF(MY_WME))) < 0)
DBUG_RETURN(-1);
my_close(create_file,MYF(0));
DBUG_RETURN(0);
}
In the preceding example, the CSV engine does
not refer at all to the *table_arg or
*create_info parameters, but simply creates the
required data files, closes them, and returns.
The my_create and my_close
functions are helper functions defined in
src/include/my_sys.h.
Before any read or write operations are performed on a table, the MySQL server will call the handler::open() method to open the table data and index files (if they exist).
int open(const char *name, int mode, int test_if_locked);
The first parameter is the name of the table to be opened. The
second parameter determines what file to open or what operation to
take. The values are defined in handler.h and
are copied here for your convenience:
O_RDONLY - Open read only O_RDWR - Open read/write
The final option dictates whether the handler should check for a lock on the table before opening it. The following options are available:
#define HA_OPEN_ABORT_IF_LOCKED 0 /* default */ #define HA_OPEN_WAIT_IF_LOCKED 1 #define HA_OPEN_IGNORE_IF_LOCKED 2 #define HA_OPEN_TMP_TABLE 4 /* Table is a temp table */ #define HA_OPEN_DELAY_KEY_WRITE 8 /* Don't update index */ #define HA_OPEN_ABORT_IF_CRASHED 16 #define HA_OPEN_FOR_REPAIR 32 /* open even if crashed */
Typically your storage engine will need to implement some form of
shared access control to prevent file corruption is a
multi-threaded environment. For an example of how to implement
file locking, see the get_share() and
free_share() methods of
sql/examples/ha_tina.cc.
The most basic storage engines implement read-only table scanning. Such engines might be used to support SQL queries of logs and other data files that are populated outside of MySQL.
The implementation of the methods in this section provide the first steps toward the creation of more advanced storage engines.
The following shows the method calls made during a nine-row table
scan of the CSV engine:
ha_tina::store_lock ha_tina::external_lock ha_tina::info ha_tina::rnd_init ha_tina::extra - ENUM HA_EXTRA_CACHE Cache record in HA_rrnd() ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::extra - ENUM HA_EXTRA_NO_CACHE End caching of records (def) ha_tina::external_lock ha_tina::extra - ENUM HA_EXTRA_RESET Reset database to after open
The
store_lock()
function is called before any reading or writing is performed.
Before adding the lock into the table lock handler mysqld calls store lock with the requested locks. Store lock can modify the lock level, for example change blocking write lock to non-blocking, ignore the lock (if we don't want to use MySQL table locks at all) or add locks for many tables (like we do when we are using a MERGE handler).
Berkeley DB, for example, downgrades blocking table
TL_WRITE locks to non-blocking
TL_WRITE_ALLOW_WRITE locks (which signals
that we are doing WRITEs, but we are still
allowing other readers and writers).
When releasing locks, store_lock() is also
called. In this case, one usually doesn't have to do anything.
If the argument of store_lock is
TL_IGNORE, it means that MySQL requests the
handler to store the same lock level as the last time.
The potential lock types are defined in
includes/thr_lock.h and are copied here:
enum thr_lock_type
{
TL_IGNORE=-1,
TL_UNLOCK, /* UNLOCK ANY LOCK */
TL_READ, /* Read lock */
TL_READ_WITH_SHARED_LOCKS,
TL_READ_HIGH_PRIORITY, /* High prior. than TL_WRITE. Allow concurrent insert */
TL_READ_NO_INSERT, /* READ, Don't allow concurrent insert */
TL_WRITE_ALLOW_WRITE, /* Write lock, but allow other threads to read / write. */
TL_WRITE_ALLOW_READ, /* Write lock, but allow other threads to read / write. */
TL_WRITE_CONCURRENT_INSERT, /* WRITE lock used by concurrent insert. */
TL_WRITE_DELAYED, /* Write used by INSERT DELAYED. Allows READ locks */
TL_WRITE_LOW_PRIORITY, /* WRITE lock that has lower priority than TL_READ */
TL_WRITE, /* Normal WRITE lock */
TL_WRITE_ONLY /* Abort new lock request with an error */
};
Actual lock handling will vary depending on your locking implementation and you may choose to implement some or none of the requested lock types, substituting your own methods as appropriate. The following is the minimal implementation, for a storage engine that does not need to downgrade locks:
THR_LOCK_DATA **ha_tina::store_lock(THD *thd,
THR_LOCK_DATA **to,
enum thr_lock_type lock_type)
{
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK)
lock.type=lock_type;
*to++= &lock;
return to;
}
See also ha_berkeley::store_lock() and
ha_myisammrg::store_lock() for a more
complex implementation.
The
external_lock()
function is called at the start of a statement or when a
LOCK TABLES statement is issued.
Examples of using external_lock() can be
found in the sql/ha_innodb.cc and
sql/ha_berkeley.cc files, but most storage
engines can simply return 0, as is the case
with the EXAMPLE storage engine:
int ha_example::external_lock(THD *thd, int lock_type)
{
DBUG_ENTER("ha_example::external_lock");
DBUG_RETURN(0);
}
The function called before any table scan is the
rnd_init()
function. The rnd_init() function is used
to prepare for a table scan, resetting counters and pointers to
the start of the table.
The following example is from the CSV storage
engine:
int ha_tina::rnd_init(bool scan)
{
DBUG_ENTER("ha_tina::rnd_init");
current_position= next_position= 0;
records= 0;
chain_ptr= chain;
DBUG_RETURN(0);
}
If the scan parameter is true, the MySQL
server will perform a sequential table scan, if false the MySQL
server will perform random reads by position.
Prior to commencing a table scan, the
info()
function is called to provide extra table information to the
optimizer.
The information required by the optimizer is not given through
return values but instead by populating certain properties of
the storage engine class, which the optimizer reads after the
info() call returns.
In addition to being used by the optimizer, many of the values
set during a call to the info() function
are also used for the SHOW TABLE STATUS
statement.
The public properties are listed in full in
sql/handler.h; several of the more common
ones are copied here:
ulonglong data_file_length; /* Length off data file */ ulonglong max_data_file_length; /* Length off data file */ ulonglong index_file_length; ulonglong max_index_file_length; ulonglong delete_length; /* Free bytes */ ulonglong auto_increment_value; ha_rows records; /* Records in table */ ha_rows deleted; /* Deleted records */ ulong raid_chunksize; ulong mean_rec_length; /* physical reclength */ time_t create_time; /* When table was created */ time_t check_time; time_t update_time;
For the purposes of a table scan, the most important property is
records, which indicates the number of
records in the table. The optimizer will perform differently
when the storage engine indicates that there are zero or one
rows in the table than it will when there are two or more. For
this reason it is important to return a value of two or greater
when you do not actually know how many rows are in the table
before you perform the table scan (such as in a situation where
the data may be externally populated).
Prior to some operations, the
extra()
function is called to provide extra hints to the storage engine
on how to perform certain operations.
Implementation of the hints in the extra
call is not mandatory, and most storage engines return
0:
int ha_tina::extra(enum ha_extra_function operation)
{
DBUG_ENTER("ha_tina::extra");
DBUG_RETURN(0);
}
After the table is initialized, the MySQL server will call the
handler's
rnd_next()
function once for every row to be scanned until the server's
search condition is satisfied or an end of file is reached, in
which case the handler returns
HA_ERR_END_OF_FILE.
The rnd_next() function takes a single byte
array parameter named *buf. The
*buf parameter must be populated with the
contents of the table row in the internal MySQL format.
The server uses three data formats: fixed-length rows,
variable-length rows, and variable-length rows with BLOB
pointers. In each format, the columns appear in the order in
which they were defined by the CREATE TABLE statement. (The
table definition is stored in the .frm
file, and the optimizer and the handler are both able to access
table metadata from the same source, its
TABLE structure).
Each format begins with a “NULL bitmap” of one bit per nullable column. A table with as many as eight nullable columns will have a one-byte bitmap; a table with nine to sixteen nullable columns will have a two-byte bitmap, and so forth. One exception is fixed-width tables, which have an additional starting bit so that a table with eight nullable columns would have a two-byte bitmap.
After the NULL bitmap come the columns, one by one. Each column
is of the size indicated in Chapter 11, Data Types. In the
server, column data types are defined in the
sql/field.cc file. In the fixed length row
format, the columns are simply laid out one by one. In a
variable-length row, VARCHAR columns are
coded as a one or two-byte length, followed by a string of
characters. In a variable-length row with
BLOB columns, each blob is represented by two
parts: first an integer representing the actual size of the
BLOB, and then a pointer to the
BLOB in memory.
Examples of row conversion (or “packing”) can be
found by starting at rnd_next() in any
table handler. In ha_tina.cc, for example,
the code in find_current_row() illustrates
how the TABLE structure (pointed to by table)
and a string object (named buffer) can be used to pack character
data from a CSV file. Writing a row back to disk requires the
opposite conversion, unpacking from the internal format.
The following example is from the CSV storage
engine:
int ha_tina::rnd_next(byte *buf)
{
DBUG_ENTER("ha_tina::rnd_next");
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count, &LOCK_status);
current_position= next_position;
if (!share->mapped_file)
DBUG_RETURN(HA_ERR_END_OF_FILE);
if (HA_ERR_END_OF_FILE == find_current_row(buf) )
DBUG_RETURN(HA_ERR_END_OF_FILE);
records++;
DBUG_RETURN(0);
}
The conversion from the internal row format to CSV row format is
performed in the find_current_row()
function:
int ha_tina::find_current_row(byte *buf)
{
byte *mapped_ptr= (byte *)share->mapped_file + current_position;
byte *end_ptr;
DBUG_ENTER("ha_tina::find_current_row");
/* EOF should be counted as new line */
if ((end_ptr= find_eoln(share->mapped_file, current_position,
share->file_stat.st_size)) == 0)
DBUG_RETURN(HA_ERR_END_OF_FILE);
for (Field **field=table->field ; *field ; field++)
{
buffer.length(0);
mapped_ptr++; // Increment past the first quote
for(;mapped_ptr != end_ptr; mapped_ptr++)
{
// Need to convert line feeds!
if (*mapped_ptr == '"' &&
(((mapped_ptr[1] == ',') && (mapped_ptr[2] == '"')) ||
(mapped_ptr == end_ptr -1 )))
{
mapped_ptr += 2; // Move past the , and the "
break;
}
if (*mapped_ptr == '\\' && mapped_ptr != (end_ptr - 1))
{
mapped_ptr++;
if (*mapped_ptr == 'r')
buffer.append('\r');
else if (*mapped_ptr == 'n' )
buffer.append('\n');
else if ((*mapped_ptr == '\\') || (*mapped_ptr == '"'))
buffer.append(*mapped_ptr);
else /* This could only happed with an externally created file */
{
buffer.append('\\');
buffer.append(*mapped_ptr);
}
}
else
buffer.append(*mapped_ptr);
}
(*field)->store(buffer.ptr(), buffer.length(), system_charset_info);
}
next_position= (end_ptr - share->mapped_file)+1;
/* Maybe use \N for null? */
memset(buf, 0, table->s->null_bytes); /* We do not implement nulls! */
DBUG_RETURN(0);
}
When the MySQL server is finished with a table, it will call the close() method to close file pointers and release any other resources.
Storage engines that use the shared access methods seen in the
CSV engine and other example engines must
remove themselves from the shared structure:
int ha_tina::close(void)
{
DBUG_ENTER("ha_tina::close");
DBUG_RETURN(free_share(share));
}
Storage engines using their own share management systems should use whatever methods are needed to remove the handler instance from the share for the table opened in their handler.
Once you have read support in your storage engine, the next
feature to implement is support for INSERT
statements. With INSERT support in place, your
storage engine can handle WORM (write once, read many)
applications such as logging and archiving for later analysis.
All INSERT operations are handled through the
write_row()
function:
int ha_foo::write_row(byte *buf)
The *buf parameter contains the row to be
inserted in the internal MySQL format. A basic storage engine
could simply advance to the end of the data file and append the
contents of the buffer directly (this would also make reading rows
easier as you could read the row and pass it directly into the
buffer parameter of the rnd_next() function.
The process for writing a row is the opposite of the process for
reading one: take the data from the MySQL internal row format and
write it to the data file. The following example is from the
MyISAM storage engine:
int ha_myisam::write_row(byte * buf)
{
statistic_increment(table->in_use->status_var.ha_write_count,&LOCK_status);
/* If we have a timestamp column, update it to the current time */
if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_INSERT)
table->timestamp_field->set_time();
/*
If we have an auto_increment column and we are writing a changed row
or a new row, then update the auto_increment value in the record.
*/
if (table->next_number_field && buf == table->record[0])
update_auto_increment();
return mi_write(file,buf);
}
Three items of note in the preceding example include the updating
of table statistics for writes, the setting of the timestamp prior
to writing the row, and the updating of
AUTO_INCREMENT values.
The MySQL server executes UPDATE statements by
performing a (table/index/range/etc.) scan until it locates a row
matching the WHERE clause of the
UPDATE statement, then calling the
update_row()
function:
int ha_foo::update_row(const byte *old_data, byte *new_data)
The *old_data parameter contains the data that
existed in the row prior to the update, while the
*new_data parameter contains the new contents
of the row (in the MySQL internal row format).
Performing an update will depend on row format and storage implementation. Some storage engines will replace data in-place, while other implementations delete the existing row and append the new row at the end of the data file.
Non-indexed storage engines can typically ignore the contents of
the *old_data parameter and just deal with the
*new_data buffer. Transactional engines may
need to compare the buffers to determine what changes have been
made for a later rollback.
If the table being updated contains timestamp columns, the
updating of the timestamp will have to be managed in the
update_row() call. The following example is
from the CSV engine:
int ha_tina::update_row(const byte * old_data, byte * new_data)
{
int size;
DBUG_ENTER("ha_tina::update_row");
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count,
&LOCK_status);
if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_UPDATE)
table->timestamp_field->set_time();
size= encode_quote(new_data);
if (chain_append())
DBUG_RETURN(-1);
if (my_write(share->data_file, buffer.ptr(), size, MYF(MY_WME | MY_NABP)))
DBUG_RETURN(-1);
DBUG_RETURN(0);
}
Note the setting of the timestamp in the previous example.
The MySQL server executes DELETE statements
using the same approach as for UPDATE
statements: It advances to the row to be deleted using the
rnd_next() function and then calls the
delete_row()
function to delete the row:
int ha_foo::delete_row(const byte *buf)
The *buf parameter contains the contents of the
row to be deleted. For non-indexed storage engines the parameter
can be ignored, but transactional storage engines may need to
store the deleted data for rollback purposes.
The following example is from the CSV storage
engine:
int ha_tina::delete_row(const byte * buf)
{
DBUG_ENTER("ha_tina::delete_row");
statistic_increment(table->in_use->status_var.ha_delete_count,
&LOCK_status);
if (chain_append())
DBUG_RETURN(-1);
--records;
DBUG_RETURN(0);
}
The steps of note in the preceding example are the update of the
delete_count statistic and the record count.
In addition to table scanning, storage engines can implement functions for non-sequential reading. The MySQL server uses these functions for certain sort operations.
The
position()
function is called after every call to
rnd_next() if the data needs to be
reordered:
void ha_foo::position(const byte *record)
The contents of *record are up to you —
whatever value you provide will be returned in a later call to
retrieve the row. Most storage engines will store some form of
offset or primary key value.
The
rnd_pos()
function behaves in a similar fashion to the
rnd_next() function but takes an additional
parameter:
int ha_foo::rnd_pos(byte * buf, byte *pos)
The *pos parameter contains positioning
information previously recorded using the
position() function.
A storage engine must locate the row specified by the position
and return it through *buf in the internal
MySQL row format.
- 15.15.1. Indexing Overview
- 15.15.2. Getting Index Information During
CREATE TABLEOperations - 15.15.3. Creating Index Keys
- 15.15.4. Parsing Key Information
- 15.15.5. Providing Index Information to the Optimizer
- 15.15.6. Preparing for Index Use with
index_init() - 15.15.7. Cleaning up with
index_end() - 15.15.8. Implementing the
index_read()Function - 15.15.9. Implementing the
index_read_idx()Function - 15.15.10. Implementing the
index_next()Function - 15.15.11. Implementing the
index_prev()Function - 15.15.12. Implementing the
index_first()Function - 15.15.13. Implementing the
index_last()Function
Once basic read/write operations are implemented in a storage engine, the next stage is to add support for indexing. Without indexing, a storage engine's performance is quite limited.
This section documents the methods that must be implemented to add support for indexing to a storage engine.
Adding index support to a storage engine revolves around two tasks: providing information to the optimizer and implementing index-related methods. The information provided to the optimizer helps the optimizer to make better decisions about which index to use or even to skip using an index and instead perform a table scan.
The indexing methods either read rows that match a key, scan a set of rows by index order, or read information directly from the index.
The following example shows the function calls made during an
UPDATE query that uses an index, such as
UPDATE foo SET ts = now() WHERE id = 1:
ha_foo::index_init ha_foo::index_read ha_foo::index_read_idx ha_foo::rnd_next ha_foo::update_row
In addition to index reading methods, your storage engine must support the creation of new indexes and be able to keep table indexes up to date as rows are added, modified, and removed from tables.
It is preferable for storage engines that support indexing to
read the index information provided during a CREATE
TABLE operation and store it for future use. The
reasoning behind this is that the index information is most
readily available during table and index creation and is not as
easily retrieved afterward.
The table index information is contained within the
key_info structure of the
TABLE argument of the
create() function.
Within the key_info structure there is a
flag that defines index behavior:
#define HA_NOSAME 1 /* Set if not duplicated records */ #define HA_PACK_KEY 2 /* Pack string key to previous key */ #define HA_AUTO_KEY 16 #define HA_BINARY_PACK_KEY 32 /* Packing of all keys to prev key */ #define HA_FULLTEXT 128 /* For full-text search */ #define HA_UNIQUE_CHECK 256 /* Check the key for uniqueness */ #define HA_SPATIAL 1024 /* For spatial search */ #define HA_NULL_ARE_EQUAL 2048 /* NULL in key are cmp as equal */ #define HA_GENERATED_KEY 8192 /* Automatically generated key */
In addition to the flag, there is an
enumerator named algorithm that specifies the
desired index type:
enum ha_key_alg {
HA_KEY_ALG_UNDEF= 0, /* Not specified (old file) */
HA_KEY_ALG_BTREE= 1, /* B-tree, default one */
HA_KEY_ALG_RTREE= 2, /* R-tree, for spatial searches */
HA_KEY_ALG_HASH= 3, /* HASH keys (HEAP tables) */
HA_KEY_ALG_FULLTEXT= 4 /* FULLTEXT (MyISAM tables) */
};
In addition to the flag and
algorithm, there is an array of
key_part elements that describe the
individual parts of a composite key.
The key parts define the field associated with the key part,
whether the key should be packed, and the data type and length
of the index part. See ha_myisam.cc for an
example of how this information is parsed.
As an alternative, a storage engine can instead follow the
example of ha_berkeley.cc and read index
information from the TABLE structure of the
handler during each operation.
As part of every table-write operation
(INSERT, UPDATE,
DELETE), the storage engine is required to
update its internal index information.
The method used to update indexes will vary from storage engine to storage engine, depending on the method used to store the index.
In general, the storage engine will have to use row information
passed in functions such as
write_row(),
delete_row(),
and
update_row()
in combination with index information for the table to determine
what index data needs to be modified, and make the needed
changes.
The method of associating an index with its row will depend on
your storage approach. The BerkeleyDB storage
engine stores the primary key of the row in the index while
other storage engines often store the row offset.
Many of the index methods pass a byte array named
*key that identifies the index entry to be
read in a standard format. Your storage engine will need to
extract the information stored in the key and translate it into
its internal index format to identify the row associated with
the index.
The information in the key is obtained by iterating through the
key, which is formatted the same as the definition in
table->key_info[.
The following example from index]->key_part[part_num]ha_berkeley.cc
shows how the BerkeleyDB storage engine takes
a key defined in *key and converts it to
internal key format:
/*
Create a packed key from a MySQL unpacked key (like the one that is
sent from the index_read()
This key is to be used to read a row
*/
DBT *ha_berkeley::pack_key(DBT *key, uint keynr, char *buff,
const byte *key_ptr, uint key_length)
{
KEY *key_info=table->key_info+keynr;
KEY_PART_INFO *key_part=key_info->key_part;
KEY_PART_INFO *end=key_part+key_info->key_parts;
DBUG_ENTER("bdb:pack_key");
bzero((char*) key,sizeof(*key));
key->data=buff;
key->app_private= (void*) key_info;
for (; key_part != end && (int) key_length > 0 ; key_part++)
{
uint offset=0;
if (key_part->null_bit)
{
if (!(*buff++ = (*key_ptr == 0))) // Store 0 if NULL
{
key_length-= key_part->store_length;
key_ptr+= key_part->store_length;
key->flags|=DB_DBT_DUPOK;
continue;
}
offset=1; // Data is at key_ptr+1
}
buff=key_part->field->pack_key_from_key_image(buff,(char*) key_ptr+offset,
key_part->length);
key_ptr+=key_part->store_length;
key_length-=key_part->store_length;
}
key->size= (buff - (char*) key->data);
DBUG_DUMP("key",(char*) key->data, key->size);
DBUG_RETURN(key);
}
In order for indexing to be used effectively, storage engines need to provide the optimizer with information about the table and its indexes. This information is used to choose whether to use an index, and if so, which index to use.
The optimizer requests an update of table information by
calling the
handler::info()
function. The info() function does not
have a return value, instead it is expected that the storage
engine will set a variety of public variables that the server
will then read as needed. These values are also used to
populate certain SHOW outputs such as
SHOW TABLE STATUS and for queries of the
INFORMATION_SCHEMA.
All variables are optional but should be filled if possible:
records- The number of rows in the table. If you cannot provide an accurate number quickly you should set the value to be greater than 1 so that the optimizer does not perform optimizations for zero or one row tables.deleted- Number of deleted rows in table. Used to identify table fragmentation, where applicable.data_file_length- Size of the data file, in bytes. Helps optimizer calculate the cost of reads.index_file_length- Size of the index file, in bytes. Helps optimizer calculate the cost of reads.mean_rec_length- Average length of a single row, in bytes.scan_time- Cost in I/O seeks to perform a full table scan.delete_length-check_time-
When calculating values, speed is more important than accuracy, as there is no sense in taking a long time to give the optimizer clues as to what approach may be the fastest. Estimates within an order of magnitude are usually good enough.
The
records_in_range()
function is called by the optimizer to assist in choosing
which index on a table to use for a query or join. It is
defined as follows:
ha_rows ha_foo::records_in_range(uint inx, key_range *min_key, key_range *max_key)
The inx parameter is the index to be
checked. The *min_key parameter is the low
end of the range while the *max_key
parameter is the high end of the range.
min_key.flag can have one of the following
values:
HA_READ_KEY_EXACT- Include the key in the rangeHA_READ_AFTER_KEY- Don't include key in range
max_key.flag can have one of the following
values:
HA_READ_BEFORE_KEY- Don't include key in rangeHA_READ_AFTER_KEY- Include all 'end_key' values in the range
The following return values are allowed:
0- There are no matching keys in the given rangenumber > 0- There is approximatelynumbermatching rows in the rangeHA_POS_ERROR- Something is wrong with the index tree
When calculating values, speed is more important than accuracy.
The
index_init()
function is called before an index is used to allow the storage
engine to perform any necessary preparation or optimization:
int ha_foo::index_init(uint keynr, bool sorted)
Most storage engines do not need to make special preparations, in which case a default implementation will be used if the method is not explicitly implemented in the storage engine:
int handler::index_init(uint idx) { active_index=idx; return 0; }
The
index_end()
function is a counterpart to the
index_init() function. The purpose of the
index_end() function is to clean up any
preparations made by the index_init()
function.
If a storage engine does not implement
index_init() it does not need to implement
index_end().
The
index_read()
function is used to retrieve a row based on a key:
int ha_foo::index_read(byte * buf, const byte * key, uint key_len, enum ha_rkey_function find_flag)
The *buf parameter is a byte array that the
storage engine populates with the row that matches the index key
specified in *key. The
key_len parameter indicates the prefix length
when matching by prefix, and the find_flag
parameter is an enumerator that dictates the search behavior to
be used.
The index to be used is previously defined in the
index_init()
call and is stored in the active_index
handler variable.
The following values are allowed for
find_flag:
HA_READ_KEY_EXACT HA_READ_KEY_OR_NEXT HA_READ_PREFIX_LAST HA_READ_PREFIX_LAST_OR_PREV HA_READ_BEFORE_KEY HA_READ_AFTER_KEY HA_READ_KEY_OR_NEXT HA_READ_KEY_OR_PREV
Storage engines must convert the *key
parameter to a storage engine-specific format, use it to find
the matching row according to the find_flag,
and then populate *buf with the matching row
in the MySQL internal row format. For more information on the
internal row format, see
Section 15.9.6, “Implementing the rnd_next() Function”.
In addition to returning a matching row, the storage engine must also set a cursor to support sequential index reads.
If the *key parameter is null the storage
engine should read the first key in the index.
The
index_read_idx()
function is identical to the
index_read()
with the exception that index_read_idx()
accepts an additional keynr parameter:
int ha_foo::index_read_idx(byte * buf, uint keynr, const byte * key,
uint key_len, enum ha_rkey_function find_flag)
The keynr parameter specifies the index to be
read, as opposed to index_read where the
index is already set.
As with the index_read() function, the
storage engine must return the row that matches the key
according to the find_flag and set a cursor
for future reads.
The
index_next()
function is used for index scanning:
int ha_foo::index_next(byte * buf)
The *buf parameter is populated with the row
that corresponds to the next matching key value according to the
internal cursor set by the storage engine during operations such
as index_read() and
index_first().
The
index_prev()
function is used for reverse index scanning:
int ha_foo::index_prev(byte * buf)
The *buf parameter is populated with the row
that corresponds to the previous matching key value according to
the internal cursor set by the storage engine during operations
such as index_read() and
index_last().
The
index_first()
function is used for index scanning:
int ha_foo::index_first(byte * buf)
The *buf parameter is populated with the row
that corresponds to the first key value in the index.
The
index_last()
function is used for reverse index scanning:
int ha_foo::index_last(byte * buf)
The *buf parameter is populated with the row
that corresponds to the last key value in the index.
This section documents the methods that must be implemented to add support for transactions to a storage engine.
Please note that transaction management can be complicated and
involve methods such as row versioning and redo logs, which is
beyond the scope of this document. Instead coverage is limited to
a description of required methods and not their implementation.
For examples of implementation, please see
ha_innodb.cc and
ha_berkeley.cc.
Transactions are not explicitly started on the storage engine
level, but are instead implicitly started through calls to
either start_stmt() or
external_lock(). If the preceding functions
are called and a transaction already exists the transaction is
not replaced.
The storage engine stores transaction information in
per-connection memory and also registers the transaction in the
MySQL server to allow the server to later issue
COMMIT and ROLLBACK
operations.
As operations are performed the storage engine will have to implement some form of versioning or logging to permit a rollback of all operations executed within the transaction.
After work is completed, the MySQL server will call either the
commit() function or the
rollback() function defined in the storage
engine's handlerton.
A transaction is started by the storage engine in response to a
call to either the start_stmt() or
external_lock() functions.
If there is no active transaction, the storage engine must start
a new transaction and register the transaction with the MySQL
server so that ROLLBACK or
COMMIT can later be called.
The first function call that can start a transaction is the
start_stmt()
function.
The following example shows how a storage engine could register a transaction:
int my_handler::start_stmt(THD *thd, thr_lock_type lock_type)
{
int error= 0;
my_txn *txn= (my_txn *) thd->ha_data[my_handler_hton.slot];
if (txn == NULL)
{
thd->ha_data[my_handler_hton.slot]= txn= new my_txn;
}
if (txn->stmt == NULL && !(error= txn->tx_begin()))
{
txn->stmt= txn->new_savepoint();
trans_register_ha(thd, FALSE, &my_handler_hton);
}
return error;
}
THD is the current client connection. It
holds state relevant data for the current client, such as
identity, network connection and other per-connection data.
thd->ha_data[my_handler_hton.slot] is a
pointer in thd to the connection-specific
data of this storage engine. In this example we use it to
store the transaction context.
An additional example of implementing
start_stmt() can be found in
ha_innodb.cc.
MySQL calls
handler::external_lock()
for every table it is going to use at the beginning of every
statement. Thus, if a table is touched for the first time, it
implicitly starts a transaction.
Note that because of pre-locking, all tables that can be
potentially used between the beginning and the end of a
statement are locked before the statement execution begins and
handler::external_lock() is called for
all these tables. That is, if an INSERT
fires a trigger, which calls a stored procedure, that invokes
a stored function, and so forth, all tables used in the
trigger, stored procedure, function, etc., are locked in the
beginning of the INSERT. Additionally, if
there's a construct like
IF .. use one table ELSE .. use another table
both tables will be locked.
Also, if a user calls LOCK TABLES, MySQL
will call handler::external_lock only
once. In this case, MySQL will call
handler::start_stmt() at the beginning of
the statement.
The following example shows how a storage engine can start a transaction and take locking requests into account:
int my_handler::external_lock(THD *thd, int lock_type)
{
int error= 0;
my_txn *txn= (my_txn *) thd->ha_data[my_handler_hton.slot];
if (txn == NULL)
{
thd->ha_data[my_handler_hton.slot]= txn= new my_txn;
}
if (lock_type != F_UNLCK)
{
bool all_tx= 0;
if (txn->lock_count == 0)
{
txn->lock_count= 1;
txn->tx_isolation= thd->variables.tx_isolation;
all_tx= test(thd->options & (OPTION_NOT_AUTOCOMMIT | OPTION_BEGIN | OPTION_TABLE_LOCK));
}
if (all_tx)
{
txn->tx_begin();
trans_register_ha(thd, TRUE, &my_handler_hton);
}
else
if (txn->stmt == 0)
{
txn->stmt= txn->new_savepoint();
trans_register_ha(thd, FALSE, &my_handler_hton);
}
}
else
{
if (txn->stmt != NULL)
{
/* Commit the transaction if we're in auto-commit mode */
my_handler_commit(thd, FALSE);
delete txn->stmt; // delete savepoint
txn->stmt= NULL;
}
}
return error;
}
Every storage engine must call
trans_register_ha() every time it starts
a transaction. The trans_register_ha()
function registers a transaction with the MySQL server to
allow for future COMMIT and
ROLLBACK calls.
An additional example of implementing
external_lock() can be found in
ha_innodb.cc.
Of the two major transactional operations,
ROLLBACK is the more complicated to
implement. All operations that occurred during the transaction
must be reversed so that all rows are unchanged from before the
transaction began.
To support ROLLBACK, create a function that
matches this definition:
int (*rollback)(THD *thd, bool all);
The function name is then listed in the
rollback (thirteenth) entry of
the handlerton.
The THD parameter is used to identify the
transaction that needs to be rolled back, while the
bool all parameter indicates whether the
entire transaction should be rolled back or just the last
statement.
Details of implementing a ROLLBACK operation
will vary by storage engine. Examples can be found in
ha_innodb.cc and
ha_berkeley.cc.
During a commit operation, all changes made during a transaction are made permanent and a rollback operation is not possible after that. Depending on the transaction isolation used, this may be the first time such changes are visible to other threads.
To support COMMIT, create a function that
matches this definition:
int (*commit)(THD *thd, bool all);
The function name is then listed in the
rollback (twelfth) entry of
the handlerton.
The THD parameter is used to identify the
transaction that needs to be committed, while the bool
all parameter indicates if this is a full transaction
commit or just the end of a statement that is part of the
transaction.
Details of implementing a COMMIT operation
will vary by storage engine. Examples can be found in
ha_innodb.cc and
ha_berkeley.cc.
If the server is in auto-commit mode, the storage engine should
automatically commit all read-only statements such as
SELECT.
In a storage engine, "auto-committing" works by counting locks.
Increment the count for every call to
external_lock(), decrement when
external_lock() is called with an argument
of F_UNLCK. When the count drops to zero,
trigger a commit.
First, the implementor should know how many bytes are required to store savepoint information. This should be a fixed size, preferably not large as the MySQL server will allocate space to store the savepoint for all storage engines with each named savepoint.
The implementor should store the data in the space preallocated by mysqld - and use the contents from the preallocated space for rollback or release savepoint operations.
When a COMMIT or ROLLBACK
operation occurs (with bool all set to
true), all savepoints are assumed to be
released. If the storage engine allocates resources for
savepoints, it should free them.
The following handlerton elements need to be implemented to support savepoints (elements 7,9,10,11):
uint savepoint_offset; int (*savepoint_set)(THD *thd, void *sv); int (*savepoint_rollback)(THD *thd, void *sv); int (*savepoint_release)(THD *thd, void *sv);
The seventh element of the handlerton is the
savepoint_offset:
uint savepoint_offset;
The savepoint_offset must be initialized
statically to the size of the needed memory to store
per-savepoint information.
The savepoint_set() function is called
whenever a user issues the SAVEPOINT
statement:
int (*savepoint_set)(THD *thd, void *sv);
The *sv parameter points to an
uninitialized storage area of the size defined by
savepoint_offset.
When savepoint_set() is called, the
storage engine needs to store savepoint information into
sv so that the server can later roll back
the transaction to the savepoint or release the savepoint
resources.
The savepoint_rollback() function is
called whenever a user issues the ROLLBACK TO
SAVEPOINT statement:
int (*savepoint_rollback) (THD *thd, void *sv);
The *sv parameter points to the storage
area that was previously passed to the
savepoint_set() function.
The savepoint_release() function is
called whenever a user issues the RELEASE
SAVEPOINT statement:
int (*savepoint_release) (THD *thd, void *sv);
The *sv parameter points to the storage
area that was previously passed to the
savepoint_set() function.
- 15.17.1. bas_ext
- 15.17.2. close
- 15.17.3. create
- 15.17.4. delete_row
- 15.17.5. delete_table
- 15.17.6. external_lock
- 15.17.7. extra
- 15.17.8. index_end
- 15.17.9. index_first
- 15.17.10. index_init
- 15.17.11. index_last
- 15.17.12. index_next
- 15.17.13. index_prev
- 15.17.14. index_read_idx
- 15.17.15. index_read
- 15.17.16. info
- 15.17.17. open
- 15.17.18. position
- 15.17.19. records_in_range
- 15.17.20. rnd_init
- 15.17.21. rnd_next
- 15.17.22. rnd_pos
- 15.17.23. start_stmt
- 15.17.24. store_lock
- 15.17.25. update_row
- 15.17.26. write_row
Purpose
Defines the file extensions used by the storage engine.
Synopsis
virtual const char ** bas_ext
( | ); |
| ; |
Description
This is the bas_ext method. It is called to
provide the MySQL server with a list of file extensions used by
the storage engine. The list returned is a null-terminated
string array.
By providing a list of extensions, storage engines can in many
cases omit the
delete_table()
function as the MySQL server will close all references to the
table and delete all files with the specified extension.
Parameters
There are no parameters for this function.
Return Values
Return value is a null-terminated string array of storage engine extensions. The following is an example from the
CSVengine:static const char *ha_tina_exts[] = { ".CSV", NullS };
Usage
static const char *ha_tina_exts[] =
{
".CSV",
NullS
};
const char **ha_tina::bas_ext() const
{
return ha_tina_exts;
}
Default Implementation
static const char *ha_example_exts[] = {
NullS
};
const char **ha_example::bas_ext() const
{
return ha_example_exts;
}
Purpose
Closes an open table.
Synopsis
virtual int close
( | void); |
| void ; |
Description
This is the close method.
Closes a table. A good time to free any resources that we have allocated.
Called from sql_base.cc, sql_select.cc, and table.cc. In
sql_select.cc it is only used to close up temporary tables or
during the process where a temporary table is converted over to
being a MyISAM table. For sql_base.cc look at
close_data_tables().
Parameters
void
Return Values
There are no return values.
Usage
Example from the CSV engine:
int ha_example::close(void)
{
DBUG_ENTER("ha_example::close");
DBUG_RETURN(free_share(share));
}
Purpose
Creates a new table.
Synopsis
virtual int create
( | name, | |
| form, | ||
info); |
| const char * | name ; |
| TABLE * | form ; |
| HA_CREATE_INFO * | info ; |
Description
This is the create method.
create() is called to create a table. The
variable name will have the name of the table. When
create() is called you do not need to open
the table. Also, the .frm file will have
already been created so adjusting
create_info is not recommended.
Called from handler.cc by
ha_create_table().
Parameters
nameforminfo
Return Values
There are no return values.
Usage
Example from the CSV storage engine:
int ha_tina::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
char name_buff[FN_REFLEN];
File create_file;
DBUG_ENTER("ha_tina::create");
if ((create_file= my_create(fn_format(name_buff, name, "", ".CSV",
MY_REPLACE_EXT|MY_UNPACK_FILENAME),0,
O_RDWR | O_TRUNC,MYF(MY_WME))) < 0)
DBUG_RETURN(-1);
my_close(create_file,MYF(0));
DBUG_RETURN(0);
}
Purpose
Deletes a row.
Synopsis
virtual int delete_row
( | buf); |
| const byte * | buf ; |
Description
This is the delete_row method.
buf will contain a copy of the row to be
deleted. The server will call this right after the current row
has been called (from either a previous
rnd_next() or index call). If you keep a
pointer to the last row or can access a primary key it will make
doing the deletion quite a bit easier. Keep in mind that the
server does not guarantee consecutive deletions. ORDER
BY clauses can be used.
Called in sql_acl.cc and
sql_udf.cc to manage internal table
information. Called in sql_delete.cc,
sql_insert.cc, and
sql_select.cc. In
sql_select it is used for removing
duplicates, while in insert it is used for
REPLACE calls.
Parameters
buf
Return Values
There are no return values.
Usage
Default Implementation
{ return HA_ERR_WRONG_COMMAND; }
Purpose
Delete all files with extension from
bas_ext().
Synopsis
virtual int delete_table
( | name); |
| const char * | name ; |
Description
This is the delete_table method.
Used to delete a table. By the time
delete_table() has been called all opened
references to this table will have been closed (and your
globally shared references released). The variable name will be
the name of the table. You will need to remove any files you
have created at this point.
If you do not implement this, the default
delete_table() is called from
handler.cc, and it will delete all files with
the file extensions returned by bas_ext().
We assume that the handler may return more extensions than were
actually used for the file.
Called from handler.cc by
delete_table and
ha_create_table(). Only used during create
if the table_flag
HA_DROP_BEFORE_CREATE was specified for the
storage engine.
Parameters
name: Base name of table
Return Values
0if we successfully deleted at least one file frombase_extand didn't get any other errors thanENOENT#: Error
Usage
Most storage engines can omit implementing this function.
Purpose
Handles table locking for transactions.
Synopsis
virtual int external_lock
( | thd, | |
lock_type); |
| THD * | thd ; |
| int | lock_type ; |
Description
This is the external_lock method.
The “locking functions for mysql” section in
lock.cc has additional comments on this topic
that may be useful to read.
This creates a lock on the table. If you are implementing a
storage engine that can handle transactions, look at
ha_berkely.cc to see how you will want to go
about doing this. Otherwise you should consider calling
flock() here.
Called from lock.cc by
lock_external() and
unlock_external(). Also called from
sql_table.cc by
copy_data_between_tables().
Parameters
thdlock_type
Return Values
There are no return values.
Default Implementation
{ return 0; }
Purpose
Passes hints from the server to the storage engine.
Synopsis
virtual int extra
( | operation); |
| enum ha_extra_function | operation ; |
Description
This is the extra method.
extra() is called whenever the server
wishes to send a hint to the storage engine. The
MyISAM engine implements the most hints.
ha_innodb.cc has the most exhaustive list of
these hints.
Parameters
operation
Return Values
There are no return values.
Usage
Most storage engines will simply return 0.
{ return 0; }
Default Implementation
By default your storage engine can opt to implement none of the hints.
{ return 0; }
Purpose
Indicates end of index scan, clean up any resources used.
Synopsis
virtual int index_end
( | ); |
| ; |
Description
This is the index_end method. Generally it
is used as a counterpart to the index_init
function, cleaning up any resources allocated for index
scanning.
Parameters
This function has no parameters.
Return Values
This function has no return values.
Usage
Clean up all resources allocated, return 0.
Default Implementation
{ active_index=MAX_KEY; return 0; }
Purpose
Retrieve first row in index and return.
Synopsis
virtual int index_first
( | buf); |
| byte * | buf ; |
Description
This is the index_first method.
index_first() asks for the first key in the
index.
Called from opt_range.cc, opt_sum.cc, sql_handler.cc, and sql_select.cc.
Parameters
buf- byte array to be populated with row.
Return Values
There are no return values.
Usage
Implementation depends on indexing method used.
Default Implementation
{ return HA_ERR_WRONG_COMMAND; }
Purpose
Signals the storage engine that an index scan is about to occur. Storage engine should allocate any resources needed.
Synopsis
virtual int index_init
( | idx, | |
sorted); |
| uint | idx ; |
| bool | sorted ; |
Description
This is the index_init method. This
function is called before an index scan, allowing the storage
engine to allocate resources and make preparations.
Parameters
idxsorted
Return Values
Usage
This function can typically just return 0 if there is no preparation needed.
Default Implementation
{ active_index=idx; return 0; }
Purpose
Return the last row in the index.
Synopsis
virtual int index_last
( | buf); |
| byte * | buf ; |
Description
This is the index_last method.
index_last() asks for the last key in the
index.
Called from opt_range.cc, opt_sum.cc, sql_handler.cc, and sql_select.cc.
Parameters
buf- byte array to be populated with matching row.
Return Values
This function has no return values.
Usage
Advance to last row in index and return row in buffer.
Default Implementation
{ return HA_ERR_WRONG_COMMAND; }
Purpose
Return next row in index.
Synopsis
virtual int index_next
( | buf); |
| byte * | buf ; |
Description
This is the index_next method.
Used to read forward through the index.
Parameters
buf
Return Values
This function has no return values.
Usage
Advance to next row in index using pointer or cursor, return row in buffer.
Default Implementation
{ return HA_ERR_WRONG_COMMAND; }
Purpose
Advance to previous row in index.
Synopsis
virtual int index_prev
( | buf); |
| byte * | buf ; |
Description
This is the index_prev method.
Used to read backward through the index.
Parameters
buf
Return Values
This function has no return values.
Usage
Move to previous row in index, retun in buffer.
Default Implementation
{ return HA_ERR_WRONG_COMMAND; }
Purpose
Find a row based on a key and return.
Synopsis
virtual int index_read_idx
( | buf, | |
| index, | ||
| key, | ||
| key_len, | ||
find_flag); |
| byte * | buf ; |
| uint | index ; |
| const byte * | key ; |
| uint | key_len ; |
| enum ha_rkey_function | find_flag ; |
Description
This is the index_read_idx method.
Positions an index cursor to the index specified in key. Fetches the row if any. This is only used to read whole keys.
Parameters
bufindexkeykey_lenfind_flag
Return Values
This function has no return values.
Usage
Locate the row that matches the key passed and return it in the buffer provided.
Purpose
Find a row based on a key and return.
Synopsis
virtual int index_read
( | buf, | |
| key, | ||
| key_len, | ||
find_flag); |
| byte * | buf ; |
| const byte * | key ; |
| uint | key_len ; |
| enum ha_rkey_function | find_flag ; |
Description
This is the index_read method.
Positions an index cursor to the index specified in the handle. Fetches the row if available. If the key value is null, begin at the first key of the index.
Parameters
bufkeykey_lenfind_flag
Return Values
This function has no return values.
Usage
Default Implementation
{ return HA_ERR_WRONG_COMMAND; }
Purpose
Prompts storage engine to report statistics.
Synopsis
virtual void info
( | uint); |
| uint ; |
Description
This is the info method.
::info() is used to return information to the optimizer. Currently, this table handler doesn't implement most of the fields really needed. SHOW also makes use of this data Another note, you will probably want to have the following in your code: if (records < 2) records = 2; The reason is that the server will optimize for cases of only a single record. If in a table scan you don't know the number of records it will probably be better to set records to two so you can return as many records as you need. Along with records a few more variables you may wish to set are: records deleted data_file_length index_file_length delete_length check_time See public variables in handler.h for more information.
Called in: filesort.cc ha_heap.cc item_sum.cc opt_sum.cc sql_delete.cc sql_delete.cc sql_derived.cc sql_select.cc sql_select.cc sql_select.cc sql_select.cc sql_select.cc sql_show.cc sql_show.cc sql_show.cc sql_show.cc sql_table.cc sql_union.cc sql_update.cc
Parameters
uint
Return Values
There are no return values.
Usage
This example is from the CSV storage engine:
void ha_tina::info(uint flag)
{
DBUG_ENTER("ha_tina::info");
/* This is a lie, but you don't want the optimizer to see zero or 1 */
if (records < 2)
records= 2;
DBUG_VOID_RETURN;
}
Purpose
Opens a table.
Synopsis
virtual int open
( | name, | |
| mode, | ||
test_if_locked); |
| const char * | name ; |
| int | mode ; |
| uint | test_if_locked ; |
Description
This is the open method.
Used for opening tables. The name will be the name of the file. A table is opened when it needs to be opened. For instance when a request comes in for a select on the table (tables are not open and closed for each request, they are cached).
Called from handler.cc by handler::ha_open(). The server opens all tables by calling ha_open() which then calls the handler specific open().
A handler object is opened as part of its initialization and before being used for normal queries (not before meta-data changes always.) If the object was opened it will also be closed before being deleted.
This is the open method.
open is called to open a database table.
The first parameter is the name of the table to be opened. The
second parameter determines what file to open or what operation
to take. The values are defined in
handler.h and are copied here for your
convenience:
#define HA_OPEN_KEYFILE 1
#define HA_OPEN_RNDFILE 2
#define HA_GET_INDEX 4
#define HA_GET_INFO 8 /* do a ha_info() after open */
#define HA_READ_ONLY 16 /* File opened as readonly */
#define HA_TRY_READ_ONLY 32 /* Try readonly if can't open with read and write */
#define HA_WAIT_IF_LOCKED 64 /* Wait if locked on open */
#define HA_ABORT_IF_LOCKED 128 /* skip if locked on open.*/
#define HA_BLOCK_LOCK 256 /* unlock when reading some records */
#define HA_OPEN_TEMPORARY 512
The final option dictates whether the handler should check for a lock on the table before opening it.
Typically your storage engine will need to implement some form
of shared access control to prevent file corruption is a
multi-threaded environment. For an example of how to implement
file locking, see the get_share() and
free_share() methods of
sql/examples/ha_tina.cc.
Parameters
namemodetest_if_locked
Return Values
There are no return values.
Usage
This example is from the CSV storage engine:
int ha_tina::open(const char *name, int mode, uint test_if_locked)
{
DBUG_ENTER("ha_tina::open");
if (!(share= get_share(name, table)))
DBUG_RETURN(1);
thr_lock_data_init(&share->lock,&lock,NULL);
ref_length=sizeof(off_t);
DBUG_RETURN(0);
}
Purpose
Provide the MySQL server with position/offset information for last-read row.
Synopsis
virtual void position
( | record); |
| const byte * | record ; |
Description
This is the position method.
position() is called after each call to rnd_next() if the data needs to be ordered. You can do something like the following to store the position: my_store_ptr(ref, ref_length, current_position);
The server uses ref to store data. ref_length in the above case
is the size needed to store current_position. ref is just a byte
array that the server will maintain. If you are using offsets to
mark rows, then current_position should be the offset. If it is
a primary key like in BDB, then it needs to
be a primary key.
Called from filesort.cc, sql_select.cc, sql_delete.cc and sql_update.cc.
Parameters
record
Return Values
This function has no return values.
Usage
Return offset or retrieval key information for last row.
Purpose
For the given range how many records are estimated to be in this range.
Synopsis
virtual ha_rows records_in_range
( | inx, | |
| min_key, | ||
max_key); |
| uint | inx ; |
| key_range * | min_key ; |
| key_range * | max_key ; |
Description
This is the records_in_range method.
Given a starting key, and an ending key estimate the number of rows that will exist between the two. end_key may be empty which in case determine if start_key matches any rows.
Used by optimizer to calculate cost of using a particular index.
Called from opt_range.cc by check_quick_keys().
Parameters
inxmin_keymax_key
Return Values
Return the approxamite number of rows.
Usage
Determine an approxamite count of the rows between the key values and return.
Default Implementation
{ return (ha_rows) 10; }
Purpose
Initializes a handler for table scanning.
Synopsis
virtual int rnd_init
( | scan); |
| bool | scan ; |
Description
This is the rnd_init method.
rnd_init() is called when the system wants the storage engine to do a table scan.
Unlike index_init(), rnd_init() can be called two times without rnd_end() in between (it only makes sense if scan=1). then the second call should prepare for the new table scan (e.g if rnd_init allocates the cursor, second call should position it to the start of the table, no need to deallocate and allocate it again
Called from filesort.cc, records.cc, sql_handler.cc, sql_select.cc, sql_table.cc, and sql_update.cc.
Parameters
scan
Return Values
There are no return values.
Usage
This example is from the CSV storage engine:
int ha_tina::rnd_init(bool scan)
{
DBUG_ENTER("ha_tina::rnd_init");
current_position= next_position= 0;
records= 0;
chain_ptr= chain;
DBUG_RETURN(0);
}
Purpose
Reads the next row from a table and returns it to the server.
Synopsis
virtual int rnd_next
( | buf); |
| byte * | buf ; |
Description
This is the rnd_next method.
This is called for each row of the table scan. When you run out of records you should return HA_ERR_END_OF_FILE. Fill buff up with the row information. The Field structure for the table is the key to getting data into buf in a manner that will allow the server to understand it.
Called from filesort.cc, records.cc, sql_handler.cc, sql_select.cc, sql_table.cc, and sql_update.cc.
Parameters
buf
Return Values
There are no return values.
Usage
This example is from the ARCHIVE storage
engine:
int ha_archive::rnd_next(byte *buf)
{
int rc;
DBUG_ENTER("ha_archive::rnd_next");
if (share->crashed)
DBUG_RETURN(HA_ERR_CRASHED_ON_USAGE);
if (!scan_rows)
DBUG_RETURN(HA_ERR_END_OF_FILE);
scan_rows--;
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count,
&LOCK_status);
current_position= gztell(archive);
rc= get_row(archive, buf);
if (rc != HA_ERR_END_OF_FILE)
records++;
DBUG_RETURN(rc);
}
Purpose
Return row based on position.
Synopsis
virtual int rnd_pos
( | buf, | |
pos); |
| byte * | buf ; |
| byte * | pos ; |
Description
This is the rnd_pos method.
Used for finding row previously marked with position. This is useful for large sorts.
This is like rnd_next, but you are given a position to use to determine the row. The position will be of the type that you stored in ref. You can use ha_get_ptr(pos,ref_length) to retrieve whatever key or position you saved when position() was called. Called from filesort.cc records.cc sql_insert.cc sql_select.cc sql_update.cc.
Parameters
bufpos
Return Values
This function has no return values.
Usage
Locate row based on position value and return in buffer provided.
Purpose
Called at the beginning of a statement for transaction purposes.
Synopsis
virtual int start_stmt
( | thd, | |
lock_type); |
| THD * | thd ; |
| thr_lock_type | lock_type ; |
Description
This is the start_stmt method.
When table is locked a statement is started by calling start_stmt instead of external_lock
Parameters
thdlock_type
Return Values
This function has no return values.
Usage
Make any preparations needed for a transaction start (if there is no current running transaction).
Default Implementation
{return 0;}
Purpose
Creates and releases table locks.
Synopsis
virtual THR_LOCK_DATA **
store_lock
( | thd, | |
| to, | ||
lock_type); |
| THD * | thd ; |
| THR_LOCK_DATA ** | to ; |
| enum thr_lock_type | lock_type ; |
Description
This is the store_lock method.
The idea with handler::store_lock() is the following:
The statement decided which locks we should need for the table for updates/deletes/inserts we get WRITE locks, for SELECT... we get read locks.
Before adding the lock into the table lock handler mysqld calls store lock with the requested locks. Store lock can modify the lock level, e.g. change blocking write lock to non-blocking, ignore the lock (if we don't want to use MySQL table locks at all) or add locks for many tables (like we do when we are using a MERGE handler).
Berkeley DB for example, downgrades blocking table TL_WRITE locks to non-blocking TL_WRITE_ALLOW_WRITE locks (which signals that we are doing WRITES, but we are still allowing other readers and writers).
When releasing locks, store_lock() are also called. In this case one usually doesn't have to do anything.
If the argument of store_lock is TL_IGNORE, it means that MySQL requests the handler to store the same lock level as the last time.
Called from lock.cc by get_lock_data().
Parameters
thdtolock_type
Return Values
There are no return values.
Usage
The following example is from the ARCHIVE
storage engine:
/*
Below is an example of how to setup row level locking.
*/
THR_LOCK_DATA **ha_archive::store_lock(THD *thd,
THR_LOCK_DATA **to,
enum thr_lock_type lock_type)
{
if (lock_type == TL_WRITE_DELAYED)
delayed_insert= TRUE;
else
delayed_insert= FALSE;
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK)
{
/*
Here is where we get into the guts of a row level lock.
If TL_UNLOCK is set
If we are not doing a LOCK TABLE or DISCARD/IMPORT
TABLESPACE, then allow multiple writers
*/
if ((lock_type >= TL_WRITE_CONCURRENT_INSERT &&
lock_type <= TL_WRITE) && !thd->in_lock_tables
&& !thd->tablespace_op)
lock_type = TL_WRITE_ALLOW_WRITE;
/*
In queries of type INSERT INTO t1 SELECT ... FROM t2 ...
MySQL would use the lock TL_READ_NO_INSERT on t2, and that
would conflict with TL_WRITE_ALLOW_WRITE, blocking all inserts
to t2. Convert the lock to a normal read lock to allow
concurrent inserts to t2.
*/
if (lock_type == TL_READ_NO_INSERT && !thd->in_lock_tables)
lock_type = TL_READ;
lock.type=lock_type;
}
*to++= &lock;
return to;
}
The following is the minimal implementation, for a storage engine that does not need to downgrade locks:
THR_LOCK_DATA **ha_tina::store_lock(THD *thd,
THR_LOCK_DATA **to,
enum thr_lock_type lock_type)
{
/* Note that if the lock type is TL_IGNORE we don't update lock.type,
preserving the previous lock level */
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK)
lock.type=lock_type;
/* the heart of the store_lock() method and it's main purpose -
storing the (possibly changed) lock level into the provided
memory */
*to++= &lock;
return to;
}
See also ha_berkeley::store_lock() and ha_myisammrg::store_lock() for more complex implementation
Purpose
Updates the contents of an existing row.
Synopsis
virtual int update_row
( | old_data, | |
new_data); |
| const byte * | old_data ; |
| byte * | new_data ; |
Description
This is the update_row method.
old_data will have the previous row record in it, while new_data will have the newest data in it.
The server can do updates based on ordering if an ORDER BY clause was used. Consecutive ordering is not guaranteed.
Currently, new_data will not have an updated auto_increament record, or and updated timestamp field. You can do these for example by doing these: if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_UPDATE) table->timestamp_field->set_time(); if (table->next_number_field && record == table->record[0]) update_auto_increment();
Called from sql_select.cc, sql_acl.cc, sql_update.cc, and sql_insert.cc.
Parameters
old_datanew_data
Return Values
There are no return values.
Usage
Default Implementation
{ return HA_ERR_WRONG_COMMAND; }
Purpose
Adds a new row to a table.
Synopsis
virtual int write_row
( | buf); |
| byte * | buf ; |
Description
This is the write_row method.
write_row() inserts a row. No
extra()
hint is given currently if a bulk load is happening. buf is a
byte array of data with a size of table->s->reclength
You can use the field information to extract the data from the native byte array type. Example of this would be: for (Field **field=table->field ; *field ; field++) { ... }
BLOBs must be handled specially:
for (ptr= table->s->blob_field, end= ptr + table->s->blob_fields ; ptr != end ; ptr++)
{
char *data_ptr;
uint32 size= ((Field_blob*)table->field[*ptr])->get_length();
((Field_blob*)table->field[*ptr])->get_ptr(&data_ptr);
...
}
See ha_tina.cc for an example of extracting all of the data as strings. ha_berkeley.cc has an example of how to store it intact by "packing" it for ha_berkeley's own native storage type.
See the note for update_row() on
auto_increments and timestamps. This case also applied to
write_row().
Called from item_sum.cc, item_sum.cc, sql_acl.cc, sql_insert.cc, sql_insert.cc, sql_select.cc, sql_table.cc, sql_udf.cc, and sql_update.cc.
Parameters
bufbyte array of data
Return Values
There are no return values.
Usage
Default Implementation
{ return HA_ERR_WRONG_COMMAND; }